

Our mantra at Thoroughbred Racing Commentary is that one race shouldn’t define a horse. And one race does not establish an inflexible relationship between two horses in a ranking system.
![]() This is one reason why we have been very comfortable with PALACE PIER as the world’s #1 racehorse according to our TRC Global Rankings algorithm – a principled system based entirely on mathematics which builds a hierarchy of talent in various categories, including that of the horses themselves. (We also rank jockeys, trainers, owners and stallions using the same approach.)
This is one reason why we have been very comfortable with PALACE PIER as the world’s #1 racehorse according to our TRC Global Rankings algorithm – a principled system based entirely on mathematics which builds a hierarchy of talent in various categories, including that of the horses themselves. (We also rank jockeys, trainers, owners and stallions using the same approach.)
Other rating and rankings systems classify horses according to their best efforts alone, no matter what else they have done, but we take the view that a horse’s career is the sum of all its parts.
Now, those parts need to be weighted accordingly, but the point here is that the weight attached to any one performance is never zero. In other words, consistency matters and opportunity cost must be counted, if you are comparing the worth of one horse against another objectively.
Entering last Sunday’s G1 Prix Jacques le Marois at Deauville, Palace Pier needed to win to maintain his status at the top of the rankings. As the table shows, he was matched against seven horses, the highest ranked of whom was #28 Poetic Flare.
Palace Pier did not impress everyone with a neck victory, but it isn’t necessary for a horse to exceed his best previous performance figure to gain rankings points because every performance tells us more about a horse, in effect reducing the uncertainty over where it lies in the hierarchy of true talent the computer is trying to establish.

Look first at the Prior column. Internally, our system never uses a single performance figure in isolation to forecast the result of a race. And forecasting is what drives our machine-learning system. Using this paradigm, the computer teaches itself how to handicap races, rather than us telling it, as this explainer underlines.
It is this that makes the TRC ranking system unique. The Prior column here is not a forecast we made before the Marois, but it is the post hoc assessment of the horse’s form now we know the result. In other words, it is after we have viewed each horse’s form in light of what they did here. Those well versed in handicapping language will know this as ‘back-handicapping’.
No, the forecast the computer is making – based only on each horse’s performances in Group and Graded races, and nothing else – is expressed by its ranking, usually preceded in our material with the #. Rankings are a function of ratings after each rating has been weighted for its recency and reliability. Only then does the computer look at each horse’s performances as a portfolio.
The Prior column is then the horse’s best rating as we see it now the Marois (and all other races this week) have been added to our database. But it is helpful here in comparing how each horse performed against its ‘personal best’. The Rating column (also shaded) is the computer’s estimate (for that is all handicap ratings can ever be) of how the horse ran based on its finishing position alone.
What we allow the computer to do that is fundamentally different from all other systems is to learn the effect of the racetrack, the distance, the going and the size of the field on the distance between horses at the finish. Anyone who knows horseracing knows it is ludicrous to think the same effort is required to win by three lengths on fast ground at Ascot compared with fast ground at Longchamp. As our explainer details, by allowing this to vary and giving the computer control of it, the performance figures of horses suddenly look a lot more consistent.
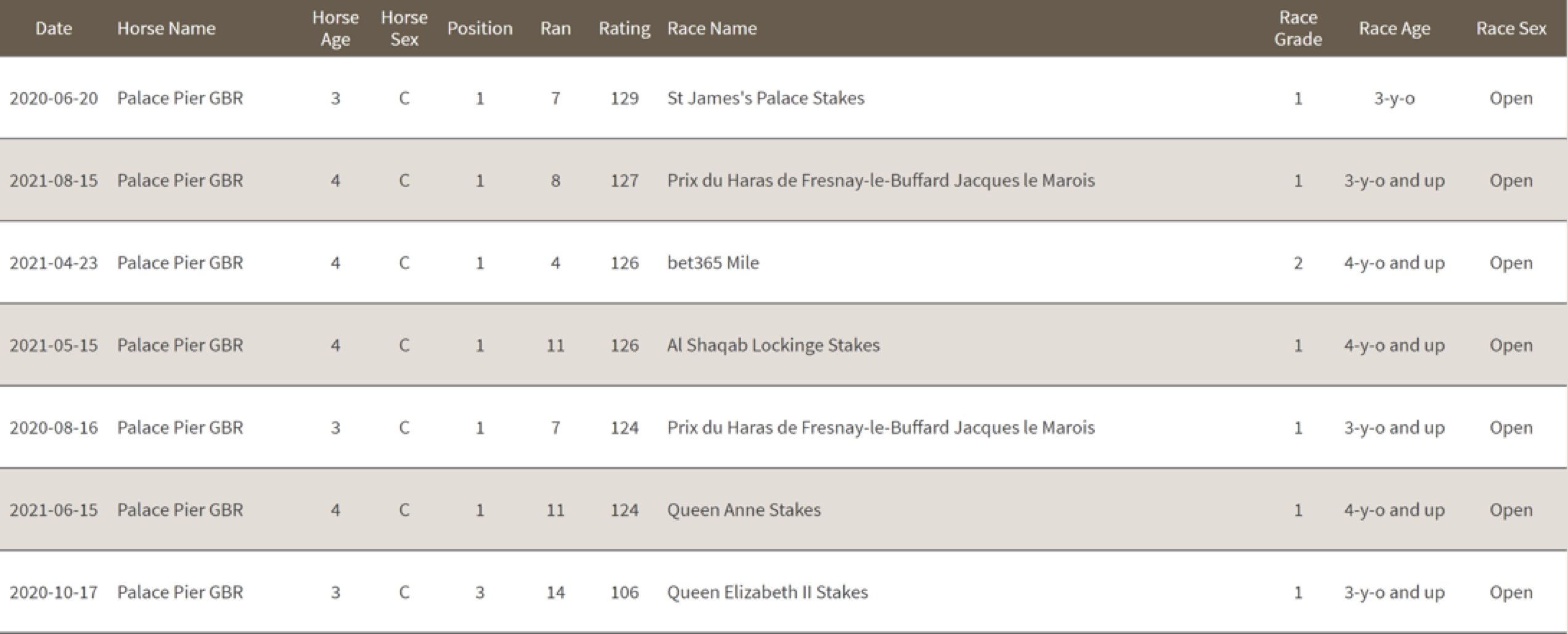
Returning to Table 1, you should be able to tell from the Rating column that the computer awarded 2pts for the neck that Palace Pier defeated Poetic Flare at Deauville. This is not the result of some human deciding he idled in front or won comfortably, but it is what the computer finds is the average difference in career ratings for a horse that beats another by a neck, weighted by the fact that this meeting took place under the conditions prevalent last Sunday.
Further, the 1¾ lengths from Poetic Flare to the Marois third Order Of Australia translates to as much as 7pts – far more than you will find in any other system. But, as you progress towards the end of the field, the gaps between horses translate to smaller difference in ratings points. Notice how we make the eight lengths that separated VictorLudorum and Alpine Star at the back of the field worth only 9pts. Again, this is because 9pts is our best guess on average as to what this difference really means in terms of the true difference in merit.
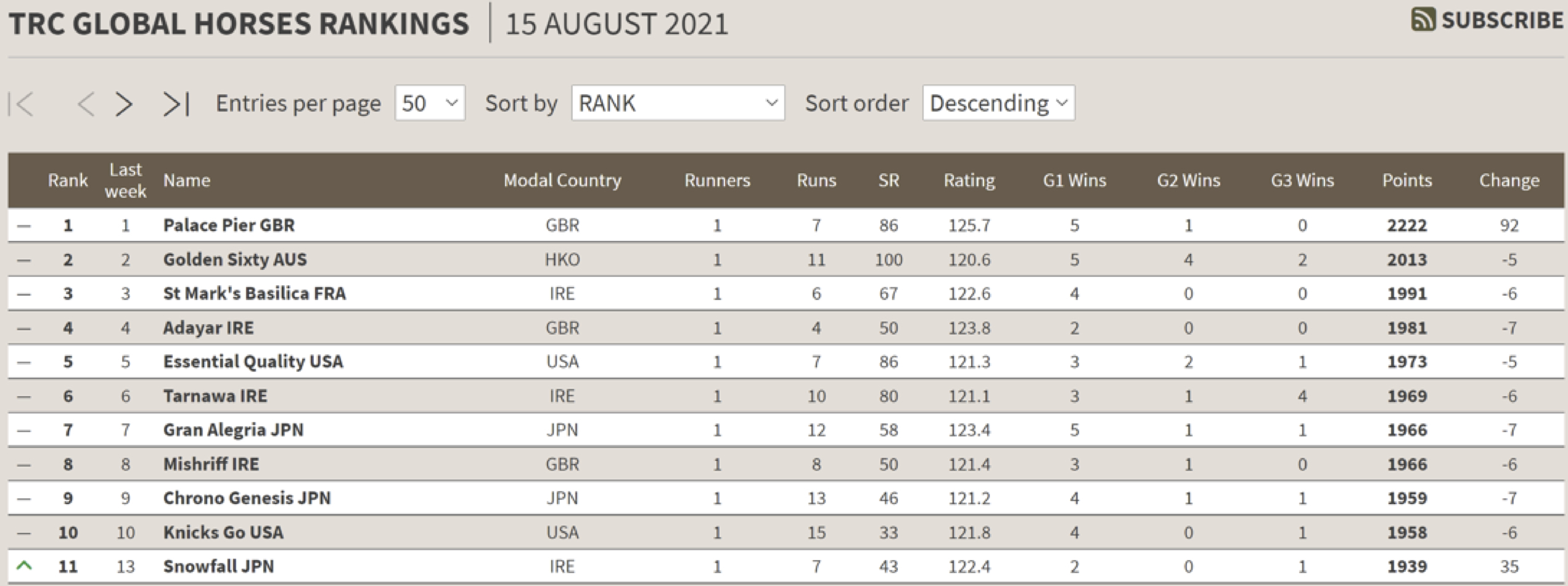
If you look at the top of the TRC Global Rankings for horses after the Marois (Table 3), you will see that Palace Pier gained rankings points for winning, even though we expected him to do so beforehand. This is because his victory provides information about his current wellbeing and that point about reducing uncertainty. In other words, the victory increases confidence that he deserves to be #1.
Incidentally, Table 3 also shows off another aspect of our system – horses can go up and down the rankings without even running if their form is represented.
Here, Snowfall moved up two spots ahead of her G1 Yorkshire Oaks bid on Thursday because her Oaks win at Epsom was given a boost by stablemate Santa Barbara winning the G1 Beverley D Stakes at Arlington (see video below).
The computer now recognises the latter as one of the best fillies in the world after she earned a TRC Computer Race Rating of 119 in Chicago. And Snowfall’s Oaks (and Irish Oaks) is now raised to 124 to reflect better the difference between them on the track when they met.
Is Palace Pier secure at #1 now for the rest of the year? Not a bit of it. As we have said many times, there are many horses ranked just below him who could surpass his rankings score (Points) even if he is retired tomorrow or never loses a race again.
Who will that be? That is the question that has many people guessing in this vintage season we are enjoying.